Test your AI for the real world
When field qualifying AI systems, it is important to know how they will perform in situations that differ from training. A big advantage of AI is that it can generalize to a wide spectrum of real world situations. Qualification AI tests evaluate whether the model performs well, or at least degrades gracefully in these cases.
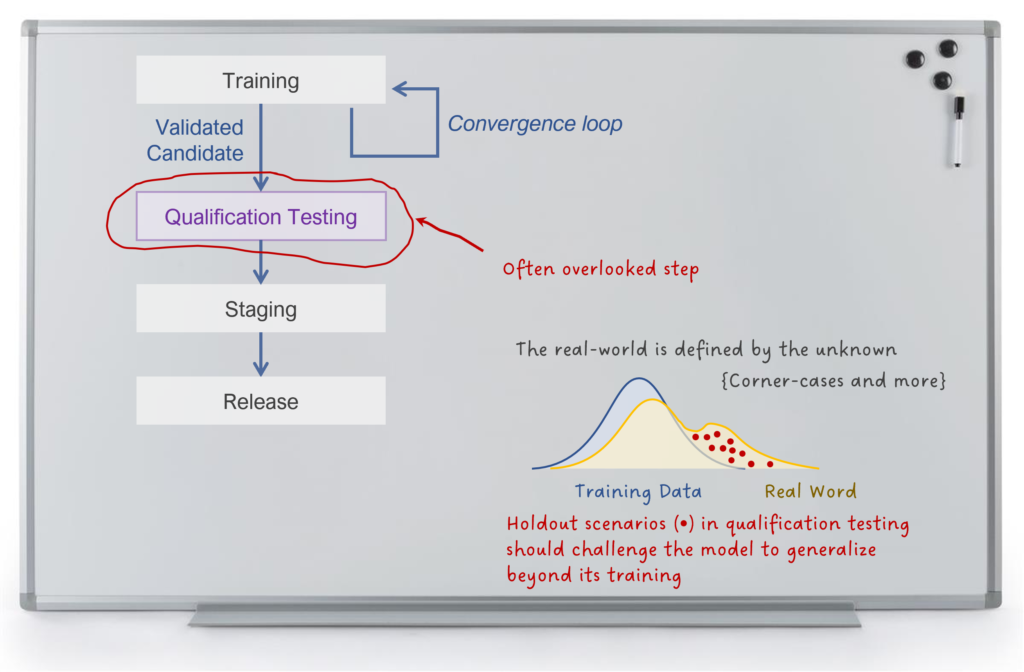
testing, an important step for field qualifying an AI system.
The tradeoff with AI is that you gain a degree of generalizability in exchange for your willingness to accept errors. All AI systems err, that’s part of the deal. Sometimes AI blunders so badly that it defies explanation. Sometimes AI simply loses a bit of accuracy or makes an honest mistake that even a human might make in the same situation.
The only thing you can be certain of is that every AI will err. Overfitting to training data causes many AI errors. The AI memorizes what to do but never develops an internal sense of the world to generalize. Other errors happen when AI is confronted with something that is radically different from training data. It could be model drift, but more often, it’s a corner case that the AI will only encounter in the real world.
When fielding any AI system, your risk is that it fails in the real world. An AI system that performs perfectly in cross-folded validation tests might stumble when exposed to the real world the first time. Or worse, it might do well in the real world, except…in situations where it doesn’t. When a technology’s core purpose is to generalize to situations it has never encountered, it becomes difficult to test. If you challenge it with something new, how well will it do? If you challenge it with something unexpected (even by you), how well will it do?
To field qualify such a system, you need a disciplined approach to out-of-distribution testing. While it is essential to use ‘holdouts’, i.e., data the model does not see during training, this is not enough. If holdout data is sampled from the same distribution as training data, then you aren’t testing the model’s ability to generalize. Such a model might not be overfit to the exact data it was trained on, but it could be overfit to that distribution of data.
For a generalizability test, you need specially curated holdout data that is from a completely different distribution. If you train the AI on apartment buildings and hold out one-fifth of your apartment buildings for validation, then at least it isn’t overfit to specific buildings. For an out-of-distribution generalizability test, you might use completely different types of apartment buildings (maybe student housing or buildings in other countries). Pushing it further, you might try testing on examples that aren’t apartment buildings, like single family homes, to see if the AI degrades gracefully.
Of course, as soon as you construct such a test, the AI engineers will want to include the validation dataset with their training data. This isn’t always a bad idea, and it isn’t always a good idea.
As part of your field qualification test, you might want an empirical measurement of how well the AI generalizes. An out-of-distribution generalizability test goes a long way toward building trust that the AI has understood, not just memorized.
An effective test strategy separate from AI model validation, is important to have in place before fielding an AI system. A product owner or project manager with AI technical skills are natural people to lead and even perform the testing. But testers should be independent and outside of the AI model development team.
AI model validation alone does not mean that your model is ready to be used in the real world. Independent testing that includes generalizability tests helps to ensure that the AI system is performing as it should.

Hi, my name is Theresa Smith. I’m a senior partner, product manager, and technology delivery lead. I have spent the last fifteen years leading product vision and initiatives using Strong Center Design. I build products that solve meaningful problems that people use around the world.