Taking AI to the Next Level
AI had a breakout year in 2022. Artificial neural networks with over a hundred-billion learnable parameters escaped their labs and fell into the laps of ordinary people. Millions of people with no AI training found themselves test-driving giant GANs, diffusion models, and transformer networks; and they had fun. Even the laughably monstrous creations couldn’t derail the positive narrative. People were astonished by the works being conjured into existence from nothing but a machine’s hallucinations; produced in seconds and guided by simple prompts. This was something new. At least it was new to everyone outside the AI community.
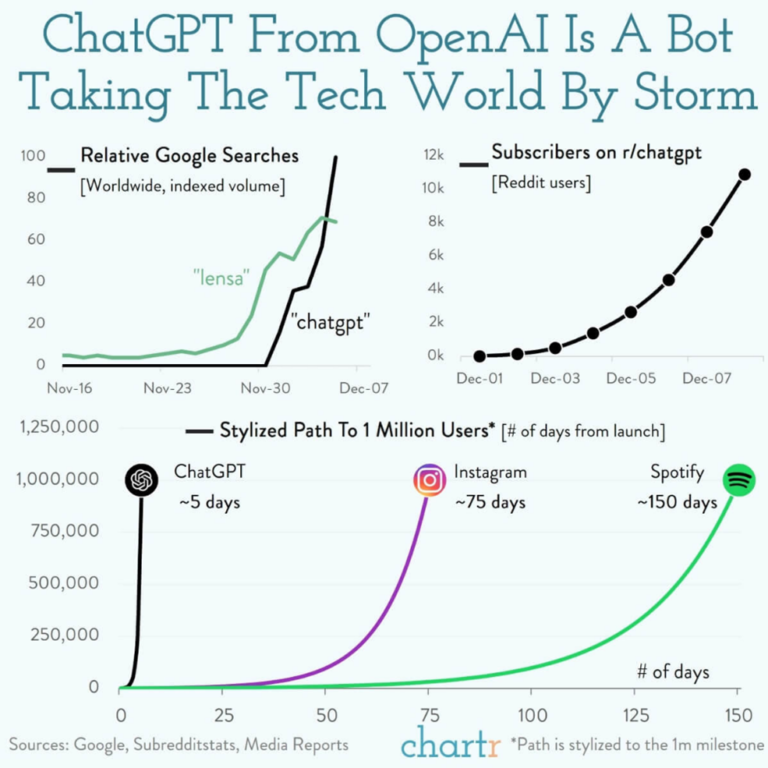
Figure 1: ChatGPT from OpenAI went from 0 to 1-million users in 5 days.
Until this year, few people had experienced an AI with over a hundred billion parameters. Except for the occasional jaunt in a self-driving car, most AI available to the public has been small model AI. This includes the AI inside smartphones, video games, recommender systems, health diagnosis, and most other things.
2022 was AI’s breakout year for two reasons: (1) millions of people were able to directly prompt a large foundation model for the first time; and (2) generative AI turned out to be the perfect format for experiencing the awesome power of today’s strongest AI. Famously, Betty Crocker cake mix only became a success after General Mills altered the original “Answer Cake” recipe to require customers to add their own egg to the mix. Adding your own egg links the finished product to you, even if yours was only a minor contribution. For AI systems, the egg people stir into the mix is the prompt. People have enjoyed contributing their own text and image prompts to ChatGPT, Stable-diffusion, Midjourney, and the year’s other escapees.

People took note when AI composed Impressive improvisations that were far more creative and technically skilled than they expected from a computer, generating in seconds what would take a human hours or days. While classification and prediction workloads are the daily grind for industrial AI, it took this massive demonstration of creativity to convince the public AI is real.
In 2022, millions of people experienced what those of us working in AI have long known, that this stuff isn’t perfect, but it is going to change everything.
However, from inside the AI community, not as much changed in 2022. GANs, diffusion models, and transformer networks have been around for a while and their potential has been widely appreciated. From the first mention of transformers in the famous 2017 Attention Is All You Need paper, insiders knew sequence-to-sequence learning was destined to be a cross-domain game changer…mainly for rich labs (more on that later).
Going forward, what BIG things are needed for AI to achieve the next level?
Challenges with today’s AI
Since conscious machines are still in the distant future, the next steps are more about raising a rapidly approaching ceiling, so we don’t run out of room to make progress. Some big problems with today’s Artificial Neural Networks (ANNs) are:
- They require unrealistic amounts of labeled training data.
- They are slow brute-force learners.
- They consume a humongous amount of energy with a massive carbon footprint.
- They can only be pretrained by large well-funded organizations.
To tabula rasa train a 200 billion parameter model, once, can cost $5 million. To own the infrastructure to support continuous training might cost $30 million to $100 million. Only well-heeled organizations can afford to create foundation models. |
Faster but less radical change
AI is advancing at a blinding pace; however, the radical advances have begun to level off. While there is an increase in research papers being written and prototypes being built, much of the new work refines rather than defines. The sequence transformer network remains king of the hill in foundation models as new research explores the infinite space between points. We are seeing an increased pace of change that is becoming less radical with each iteration. This is a healthy sign of maturity for an expanding field. However, despite the inevitability of maturity, there is still plenty of room for big ideas in AI.
Room for BIG ideas
AI’s escape from the lab in 2022 has drawn attention to the promise of strong AI and the weakness of our current neural network architectures. Here are a few areas where big ideas could return the community to a state of radical rather than incremental change:
1. Multi-modal artificial neurons: The world needs a more realistic model for individual artificial neurons. Artificial neural networks might be inspired by biological structures, but this has always been a generous analogy. Artificial neurons are comically unsophisticated compared to their biological namesakes. The activation function at the heart of an artificial neuron is a naïve bit of arithmetic with a learnable weight parameter (thank you Hodgkin-Huxley). A single artificial neuron does not have any innate macro functionality, performs no complex calculations, stores no data, and has no capacity for doing work. By comparison, real-world biological neurons are microscopic animals. They are tiny computational machines with complex latent behaviors, sophisticated sub-systems, and multiple unmapped modalities. A more bio-realistic artificial neuron would likely offer several advantages:
a. Less helpless on initialization.
b. Not as dependent on contrastive training to stabilize function.
c. Reduced need for costly backpropagation algorithms like gradient descent.
d. Increased role in memory and encoding.
e. Simplify interneural structures required to perform high-level functions.
All this translates to acquiring greater function per watt consumed in training, less dependence on massive amounts of high-quality labeled training datasets, faster time to value, and (potentially) a more generalizable AI.
2. More diverse (specialized) artificial neurons: While on the topic of bio-realism, an elephant in the room is the lack of specialization in artificial neurons. While today’s AI might use a ReLU activation function in some layers and switch to a sigmoid function in other layers, this lands far from architectural diversity. Consider that a small highly specialized region of animal cortex contains more than 250 distinct neuron species and that there are many thousands of neuron species in a mammal brain. Building ANNs as we do today is like building a computer circuit board with one type of part. Instead of having the appropriate transistor, capacitor, resistor, diode, or inductor – you have one spec for each component. While it might be possible to get something working, the result is inefficient at every level. This is how today’s ANNs compare to biological networks. Our performance per watt is abysmal and nascent untrained networks cannot do anything useful.
3. Backpropagation must go: Before an ANN can be used for inference, an instance must be trained. During training, we ask the nascent ANN to make an uneducated inference (a guess), then we compare its naïve guess to the correct answer. This is done with a loss function (computes a numeric difference between the correct answer and the guess) or a reward function (computes a numeric score representing the value of the outcome). In either case, the loss or reward is backpropagated through the artificial neural network, where each learnable weight parameter at the core of each neuron is delicately adjusted to improve the result. This is computationally intensive. It is also unsustainable. In today’s world of hundred-billion-parameter models, this requires hundreds of thousands of GPU hours, costing millions of dollars, and driving a massive carbon footprint. We know that biological neural networks do not use backpropagation as a principal mechanism. In biology, neuron function is acquired and stabilized in other ways. In some cases, function is hereditary and in other cases it is acquired through few-shot learning (learning from a small number of examples). Other modalities might also be at play. Big ideas that reduce or eliminate today’s dependence on backpropagation will immediately terraform the AI landscape. The functional and economic benefits are exponential.
4. A model for memory. It is often a surprise to people outside the community that most AI has little to no memory. The forward pass of a conventional neural network (where it turns inputs into outputs) has no persistent memory. A complex recurrent neural network has a limited amount of short-term memory for immediate tasks but can’t recall anything useful from yesterday or last year. ANNs are essentially born with Alzheimer’s. In a general sense, we lack a universal encoding system for perception and an architecture for storing and finding all-purpose information. At some point, people will expect their AI to remember what it is told, keep facts straight, and use acquired knowledge to solve problems. We cannot continue to forever rely on factory updates to productionize all aspects of learning.
5. Trillion-parameter (neuron) models: Today’s large language models tend to be in the 175 billion parameter neighborhood. Image generators like DALL-E 2, Stable-diffusion, and Midjourney tend to be much smaller (under 5 billion parameters). From the perspective of generalizable AI, more parameters make better outcomes; the so-called ‘blessing of scale’. However, more parameters also bring more problems. We quickly get to a point where the amount of data required to properly train a large network is so immense that it exceeds all available data in the solar system. Underfeeding a large neural network with training data results in the network performing badly, typically by overfitting (memorizing the training material). AI engineers tend to keep making a model larger until they run out of data or money. The resulting equilibrium imposes a ceiling (hence why image generators are not as large as language models). Today’s 175 billion parameter large language models already train on almost every available piece of text on Earth. Going to 500 billion parameters is not currently practical. Such a network would be undersaturated by the available data. Moreover, even if data was not a limitation, there is the matter of hardware and wattage. Training a 175 billion parameter foundation model is already limited to those who can afford elite resources. Google claims to have trained a trillion-parameter model, but this is not something anyone wants to do repeatedly (not even with Google’s money). Such a model is cost prohibitive to train and cost prohibitive to host for inference – so there is no point to having it. To overcome this ceiling, we need two breakthroughs: (1) hardware that directly implements nanoscale artificial neurons and interneural connections; and (2) a radically different approach to ANNs that does not need planetary magnitude datasets to acquire the next level of skill.
For now, the pace of incremental change will continue to accelerate the impressive progress made every day. The innovation ceiling is coming, but we have time. That said, almost all textual data that exists for training a large foundation model has already been used for that purpose. As the industry expands from specialized text-only or image-only models to multi-domain (all-in-one) general models, the datasets will be even less available.
Some of these issues must be addressed for AI to fully mature as a civilization-defining innovation. There’s a lot to do in 2023.